
DeepSeek R1和V3是深度求索(DeepSeek)人工智能基础研究有限公司推出的两款人工智能模型,它们在模型定位、核心能力、训练方法及应用场景等方面存在显著差异。以下是两者的详细对比:

|
项目 |
DeepSeek R1 |
DeepSeek V3 |
|
模型定位 |
专注于复杂逻辑推理任务,为需要深度逻辑分析和问题解决的场景而设计。 |
定位为通用型大语言模型,适用于多种自然语言处理任务,强调可扩展性和高效处理。 |
|
核心能力 |
擅长数学证明、代码生成、决策优化等场景。通过强化学习激发推理能力,在回答前展示“思维链”(Chain-of-Thought),增强透明度。 |
支持多模态任务(文本、图像、音频等)和长文本处理。在内容生成、多语言翻译、智能客服等场景表现出色。 |
|
训练方法 |
基于强化学习训练,摒弃了监督微调(SFT),通过强化学习激发推理能力。采用冷启动数据,进行多阶段训练。 |
采用混合精度FP8训练,训练过程分为高质量训练、扩展序列长度、进行SFT和知识蒸馏的后训练三个阶段。 |
|
模型架构 |
稠密Transformer架构,适合处理长上下文,但计算资源消耗较高。 |
采用混合专家(MoE)架构,总参数量达6710亿,每个token激活370亿参数,通过动态路由机制优化计算成本。 |
|
性能表现 |
在需要逻辑思维的基准测试中表现出色,如DROP任务中F1分数达到92.2%,AIME 2024中通过率为79.8%。 |
在数学、多语言任务以及编码任务中表现优秀,如Cmath中得分90.7%,Human Eval编码任务中通过率为65.2%。整体性能优于其他开源模型,与领先的闭源模型相当。 |
|
应用场景 |
适用于科学研究、算法交易、代码生成等需要深度逻辑分析和问题解决的场景。也适合作为教育工具,帮助学生进行逻辑思维训练。 |
适用于大规模自然语言处理任务,如对话式AI、多语言翻译和内容生成等,能够为企业提供高效的AI解决方案,满足多领域的应用需求。 |
|
其他特点 |
提供了不同规模的蒸馏版本,参数范围在15亿到700亿之间,以降低计算资源需求并保持高精度与强泛化能力。 |
率先采用无辅助损失的负载均衡策略和多令牌预测技术,提高训练效率和性能。训练成本仅为同类闭源模型的1/20。 |

总结:
- DeepSeek R1:专注于复杂逻辑推理任务,通过强化学习实现专业领域的推理突破,适合需要深度推理和复杂逻辑分析的任务。
- DeepSeek V3:定位为通用型大语言模型,以低成本和高通用性见长,支持多模态任务,适用于多种自然语言处理场景,满足多领域的应用需求。
两者各有优势,用户可以根据具体需求选择合适的模型版本。
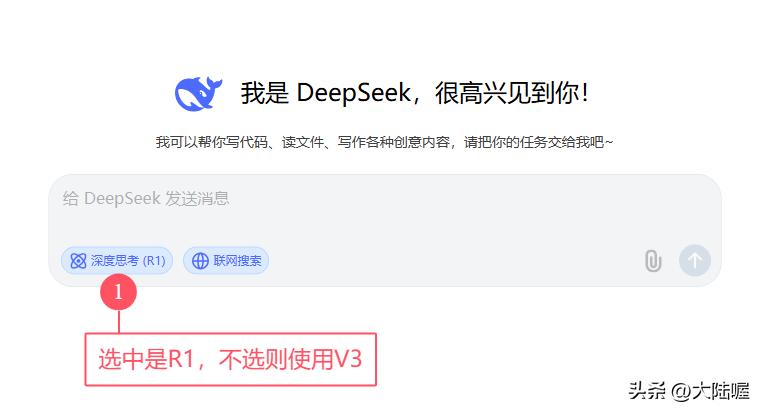
deepseek官网网页版和手机APP中,默认使用的是deepseek V3,只有选择了r1才是使用deepseek r1。
更多关于deepseek的使用、经验和技巧,以及ai相关知识,持续分享中,欢迎关注
最新业务:世纪货币网









